
As Control was a startup our entire stack of technology was architected from the ground up. Product management required a combination of myself stick-handling the design and development of our iOS, Android, and web apps as well as the stack of back-end services that supported the client-side User Interfaces (UIs). The front-end and back-end were inextricably linked and needed to evolve together in step.
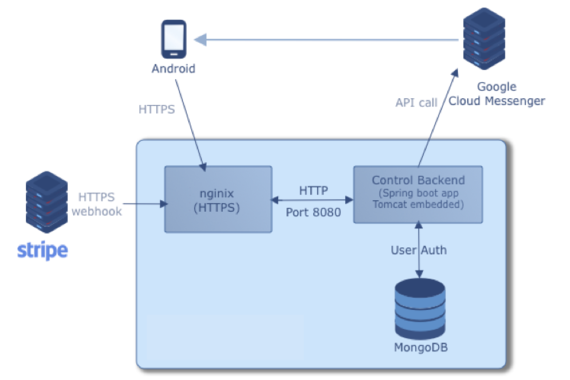
Version 1
The initial architecture of the Control back-end was a straight-forward web application using Tomcat embedded via Spring Boot and data storage via MongoDB.
A service API handles webhooks from Stripe via Spring Web MVC. One server contains the WebApp, MongoDB server, and a NGNIX (to proxy HTTPS calls to backend).
When an event occurs in the client’s Stripe account, a webhook is triggered. The back-end process the webhook calls and sends push calls to all subscribed devices via Google Cloud Messenger.
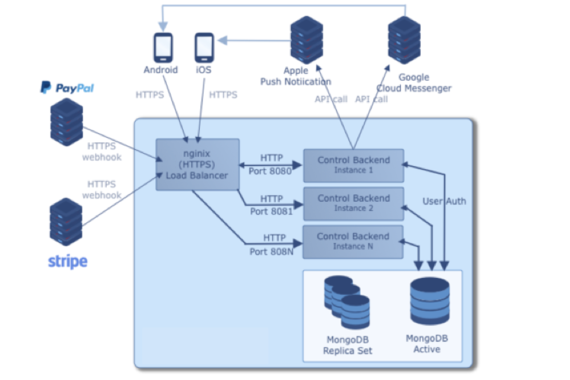
Version 2
When I acquired a competing iOS app and integrated with PayPal our user base doubled along with the number of webhooks and volume of data we were processing.
As a first increment to improving performance and scalability we started vertical clustering of our tech stack. This meant having several control-back-end instances being load balanced through ngnix, and creating multiple instances of MongoDB replicas.
Growing Pains
Our partner Stripe was growing exponentially as retail moved online and developers evangelized their APIs. In step the number of Stripe merchants connecting to Control increased as did the volume of data we were extracting and storing on their behalf. With the PayPal integration came the historical data of merchants who had been using the platform over a decade.
Our basic tech stack was getting pummeled by 24/7 server calls, our databases were straining under the weight, our back-end engineers were being monopolized by DevOps issues, and customers were complaining about data visualization bugs.

Opportunity
Our main product roadmap deliverables were to integrate to as many payment processors as possible; Square , Authorize.net and Cybersource were up next. Via customer interviews I learned that by translating complex transactional data into meaningful information for merchants delivered critical value to business users without the internal resources to do this themselves.
However, I started to put some work into strategically looking at our internal capabilities and realized the bigger opportunity was around building more complex insights around this valuable data asset that Control was accumulating.
My research illustrated that Control was in a position to deliver unique and proprietary technology and data processing capabilities to larger, up-market clients such as Visa.

ETL at Scale
I would need to lead building a system that could extract, transform, and load a large variety of datasets into storage at scale. This would allow us to provide new levels of business intelligence to our customers , such as benchmarking and predictive analytics. We needed our tech stack to match our big data ambitions.
Version 3
I took a step back to look at the entire design of our tech stack, from the back-end architecture to the iOs & Android apps, plus our newly matured web app.
We built the ‘Control API’ which consisted of three layers:
- The bottom Data Access Layer to process data from various databases with minimal logic.
- The middle Business Logic Layer to figure out what to get from the database and performs any calculations required by the interface.
- The top Interface Layer where requests are mapped to various controllers. Controllers used the business logic layer to retrieve the correct information and present it to the client.

Migration and Cut-Over
During this time I also managed the migration of the entire stack off basic Linode cloud hosting to the more scalable Google Cloud Platform. Our databases were moved to NoSQL CouchDB for optimized data-warehousing. Data object retrieval was performed via a mySQL and caching via Redis.
We ran the new stack in a staging environment while supporting the existing apps on the legacy stack. After two months of stress testing and QA, we made the cut-over during a 6 hour outage period in October 2016. We were able to migrate all of our customers and their 2TB of historical data over to the new stack and redesigned apps with minimal impact.
Our scalability increased by a factor of 40x. Our new noSQL/mySQL database strategy allowed us to start applying machine learning models to our data asset and develop a new revenue line around data monetization.